

Arkavidia Notebook

This notebook belongs to Sour Soup Team
Cross Sell Transactions
Pada notebook ini, kami akan memprediksi apakah akan terjadi cross sell pada transaksi penerbangan pelanggan tiket.com, proses ini dikategorikan sebagai klasifikasi. Cross sell adalah ketika pelanggan membuat booking hotel bersamaan dengan membeli tiket pesawat.
Tiket.com adalah situs web yang menyediakan layanan pemesanan hotel, tiket pesawat, tiket kereta api, penyewaan mobil, tiket konser, tiket atraksi, tiket hiburan, dan tiket event yang berbasis di Jakarta, Indonesia.
Untuk melakukan proses klasifikasi, kami menggunakan alur data science yang umum digunakan pada gambar dibawah ini:

Import Library
Tools yang akan digunakan pada seluruh proses.
# helper libraries
from __future__ import print_function
import os
import gc
import ast
import csv
import datetime
import random
import numpy as np
import pandas as pd
import pandas_profiling as pp
from scipy.special import expit
# data visualization
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["figure.figsize"] = [8,8]
# Model libraries
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, AdaBoostClassifier, VotingClassifier
# Helper
from sklearn.feature_selection import SelectKBest, SelectFromModel
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder
from sklearn.metrics import SCORERS, f1_score, make_scorer, classification_report, f1_score
from sklearn.model_selection import train_test_split, KFold, StratifiedKFold, cross_val_score
# Imblearn libraries
from imblearn.combine import SMOTEENN
from imblearn.pipeline import Pipeline, make_pipeline
from imblearn.over_sampling import RandomOverSampler, SMOTE, ADASYN
# add path to directory
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
Using TensorFlow backend.
/kaggle/input/datavidia2019/flight.csv
/kaggle/input/datavidia2019/sample_submission.csv
/kaggle/input/datavidia2019/Data Dictionary.pdf
/kaggle/input/datavidia2019/hotel.csv
/kaggle/input/datavidia2019/test.csv
Dataset
Berikut ini data yang tersedia dan akan digunakan untuk proses klasifikasi:
flight.csv- Data training yang berisi berbagai flight transactions beserta atribut-atributnyahotel.csv- Berisi data hotel dan atribut-atributnyatest.csv- Data test yang berisi flight transactions yang harus diprediksi apakah terjadi cross selling atau tidaksample_submission.csv- Berisi format submisi ke Kaggle
# directory kernel
dirname = '/kaggle/input/datavidia2019/'
# dataframes for each files
df_hotel = pd.read_csv(dirname+'hotel.csv')
df_flight = pd.read_csv(dirname+'flight.csv')
df_test = pd.read_csv(dirname+'test.csv')
sample = pd.read_csv(dirname+'sample_submission.csv')
Data Penerbangan
Data yang terdapat pada file flight.csv memiliki fitur sebagai berikut:
account_id: unique key dari pelanggan tiket.comorder_id: unique key dari pesanan pelangganmember_duration_days: durasi member pelanggan sejak awal mendaftargender: jenis kelamintrip: tipe perjalananservice_class: tipe layanan maskapaiprice: harga penerbanganis_tx_promo: penggunaan promosi saat transaksi penerbanganno_of_seats: jumlah kursi yang dipesan pelangganairlines_name: nama maskapairoute: rute penerbanganhotel_id: unique key dari hotel yang dipesanvisited_city: daftar kota yang telah dikunjungi pelangganlog_transaction: daftar pengeluaran yang telah dihabiskan pelanggan
adapun tampilan 5 data teratas pada file flight.csv sebagai berikut:
df_flight.head()
| account_id | order_id | member_duration_days | gender | trip | service_class | price | is_tx_promo | no_of_seats | airlines_name | route | hotel_id | visited_city | log_transaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 912aa410a02cd7e1bab414214a7005c0 | 5c6f39c690f23650d3cde28e5b51c908 | 566.0 | M | trip | ECONOMY | 885898.00 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | CGK - DPS | None | '['Semarang', 'Jakarta', 'Medan', 'Bali']' | '[545203.03, 918492.11, 1774241.4, 885898.0]' |
| 1 | d64a90a618202a5e8b25d8539377f3ca | 5cbef2b87f51c18bf399d11bfe495a46 | 607.0 | M | trip | ECONOMY | 2139751.25 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Jakarta', 'Medan', 'Bali']' | '[555476.36, 2422826.84, 7398697.64, 7930866.8... |
| 2 | 1a42ac02bcb4a902973123323f84da55 | 38fc35a1e62384012a358ab1fbd5ad03 | 648.0 | F | trip | ECONOMY | 2695550.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Semarang', 'Jakarta', 'Medan', 'Bali']' | '[7328957.45, 7027662.34, 1933360.88, 3461836.... |
| 3 | 92cddd64d4be4dec6dfbcc0c50e902f4 | c7f54cb748828b4413e02dea2758faf6 | 418.0 | F | trip | ECONOMY | 1146665.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Jogjakarta', 'Bali', 'Jakarta', 'Medan']' | '[5243631.69, 2474344.48, 1146665.0]' |
| 4 | bf637abc47ea93bad22264f4956d67f6 | dec228e4d2b6023c9f1fe9cfe9c451bf | 537.0 | F | trip | ECONOMY | 1131032.50 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | CGK - DPS | None | '['Jakarta', 'Bali', 'Medan', 'Jogjakarta', 'S... | '[9808972.98, 9628619.79, 6712680.0, 5034510.0... |
Data Hotel
Data yang terdapat pada file hotel.csv memiliki fitur sebagai berikut:
hotel_id: unique key dari hotel yang dipesanstarRating: rating hotelcity: kota hotel beradafree_wifi: fasilitas wifi gratispool_access: fasilitas kolam renangfree_breakfast: fasilitas sarapan gratis
adapun tampilan 5 data teratas pada file hotel.csv sebagai berikut:
df_hotel.head()
| hotel_id | starRating | city | free_wifi | pool_access | free_breakfast | |
|---|---|---|---|---|---|---|
| 0 | e2733e84102226acf6b53bffd2e60cf8 | 0.0 | bali | YES | NO | NO |
| 1 | 9f9de5df06d64ada1026e930687a87e4 | 0.0 | bali | YES | NO | NO |
| 2 | 3cf6774fb4dc331bb49e7a959b74a67e | 0.0 | bali | YES | NO | NO |
| 3 | eca261898220478834072b0c753a5229 | 0.0 | bali | YES | NO | NO |
| 4 | c21f400013fa4f244a7168a3c155b8b5 | 0.0 | bali | YES | NO | NO |
Data Preprocessing
Pada bagian data preprocessing, kami melakukan dua proses. Pertama, kami membuat dataframe baru yaitu df_train dan fitur baru pada dataframe tersebut sebagai variabel target yaitu is_cross_sell. Fitur is_cross_sell berdasarkan pada fitur hotel_id pada df_train. Jika hotel_id bernilai None maka tidak terjadi cross selling pada transaksi tersebut (yes) dan sebaliknya (no).
Kedua, kami mengubah tipe data fitur log_transaction dan visited_city masing-masing diubah dari string menjadi list dan tuple.
df_train = df_flight.copy()
df_train['is_cross_sell'] = ~(df_flight['hotel_id']=='None')
Helper functions dibawah ini adalah untuk membantu mengubah data object string menjadi list, sehingga fitur dapat diolah dengan baik.
def string_to_list(x):
x = ast.literal_eval(x)
x = ast.literal_eval(x)
return x
def string_to_list2(x):
x = x.strip()
x = ast.literal_eval(x)
return x
Helper function dibawah ini berfungsi untuk mengekstrak nilai yang terdapat pada fitur log_transaction. Pada fitur tersebut akan kami ubah tipe datanya menjadi list sehingga kami dapat diambil nilai max, min, mean, sum, std, dan panjang dari list masing-masing baris.
def log_tx(df):
df['log_transaction'] = df['log_transaction'].apply(string_to_list)
df['max_log_transaction'] = df['log_transaction'].apply(max)
df['min_log_transaction'] = df['log_transaction'].apply(min)
df['mean_log_transaction'] = df['log_transaction'].apply(np.mean)
df['len_log_transaction'] = df['log_transaction'].apply(len)
df['sum_log_transaction'] = df['log_transaction'].apply(np.sum)
df['sum_log_transaction'] = df['log_transaction'].apply(np.std)
df.drop(['log_transaction'],inplace=True,axis=1)
log_tx(df_train)
log_tx(df_test)
gc.collect()
648
data train yang telah melalui preprocessing menggunakan helper functions diatas adalah sebagai berikut:
df_train.head()
| account_id | order_id | member_duration_days | gender | trip | service_class | price | is_tx_promo | no_of_seats | airlines_name | route | hotel_id | visited_city | is_cross_sell | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 912aa410a02cd7e1bab414214a7005c0 | 5c6f39c690f23650d3cde28e5b51c908 | 566.0 | M | trip | ECONOMY | 885898.00 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | CGK - DPS | None | '['Semarang', 'Jakarta', 'Medan', 'Bali']' | False | 1774241.40 | 545203.03 | 1.030959e+06 | 4 | 4.533539e+05 |
| 1 | d64a90a618202a5e8b25d8539377f3ca | 5cbef2b87f51c18bf399d11bfe495a46 | 607.0 | M | trip | ECONOMY | 2139751.25 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Jakarta', 'Medan', 'Bali']' | False | 18685958.20 | 555476.36 | 2.646397e+06 | 1086 | 2.624008e+06 |
| 2 | 1a42ac02bcb4a902973123323f84da55 | 38fc35a1e62384012a358ab1fbd5ad03 | 648.0 | F | trip | ECONOMY | 2695550.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Semarang', 'Jakarta', 'Medan', 'Bali']' | False | 7328957.45 | 1933360.88 | 4.489474e+06 | 5 | 2.250021e+06 |
| 3 | 92cddd64d4be4dec6dfbcc0c50e902f4 | c7f54cb748828b4413e02dea2758faf6 | 418.0 | F | trip | ECONOMY | 1146665.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | '['Jogjakarta', 'Bali', 'Jakarta', 'Medan']' | False | 5243631.69 | 1146665.00 | 2.954880e+06 | 3 | 1.706745e+06 |
| 4 | bf637abc47ea93bad22264f4956d67f6 | dec228e4d2b6023c9f1fe9cfe9c451bf | 537.0 | F | trip | ECONOMY | 1131032.50 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | CGK - DPS | None | '['Jakarta', 'Bali', 'Medan', 'Jogjakarta', 'S... | False | 13563940.00 | 951639.00 | 4.362199e+06 | 157 | 3.006539e+06 |
Helper function dibawah ini berfungsi untuk mengubah tipe data fitur visited_city. Pada fitur tersebut akan kami ubah tipe datanya menjadi dari string menjadi list tapi karena list ada tipe data yang unhashable maka kami mengubah lagi menjadi tuple agar dapat di modifikasi.
def visited_pre(df):
df['visited_city'] = df['visited_city'].apply(lambda x: x[1:-1])
df['visited_city'] = df['visited_city'].apply(string_to_list2)
df['visited_city'] = df['visited_city'].apply(tuple)
visited_pre(df_train)
visited_pre(df_test)
data train yang telah melalui preprocessing menggunakan helper function diatas adalah sebagai berikut:
df_train.head()
| account_id | order_id | member_duration_days | gender | trip | service_class | price | is_tx_promo | no_of_seats | airlines_name | route | hotel_id | visited_city | is_cross_sell | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 912aa410a02cd7e1bab414214a7005c0 | 5c6f39c690f23650d3cde28e5b51c908 | 566.0 | M | trip | ECONOMY | 885898.00 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | CGK - DPS | None | (Semarang, Jakarta, Medan, Bali) | False | 1774241.40 | 545203.03 | 1.030959e+06 | 4 | 4.533539e+05 |
| 1 | d64a90a618202a5e8b25d8539377f3ca | 5cbef2b87f51c18bf399d11bfe495a46 | 607.0 | M | trip | ECONOMY | 2139751.25 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | (Jakarta, Medan, Bali) | False | 18685958.20 | 555476.36 | 2.646397e+06 | 1086 | 2.624008e+06 |
| 2 | 1a42ac02bcb4a902973123323f84da55 | 38fc35a1e62384012a358ab1fbd5ad03 | 648.0 | F | trip | ECONOMY | 2695550.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | (Semarang, Jakarta, Medan, Bali) | False | 7328957.45 | 1933360.88 | 4.489474e+06 | 5 | 2.250021e+06 |
| 3 | 92cddd64d4be4dec6dfbcc0c50e902f4 | c7f54cb748828b4413e02dea2758faf6 | 418.0 | F | trip | ECONOMY | 1146665.00 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | CGK - DPS | None | (Jogjakarta, Bali, Jakarta, Medan) | False | 5243631.69 | 1146665.00 | 2.954880e+06 | 3 | 1.706745e+06 |
| 4 | bf637abc47ea93bad22264f4956d67f6 | dec228e4d2b6023c9f1fe9cfe9c451bf | 537.0 | F | trip | ECONOMY | 1131032.50 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | CGK - DPS | None | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | False | 13563940.00 | 951639.00 | 4.362199e+06 | 157 | 3.006539e+06 |
Exploratory Data Analysis (EDA)
Visualisasi
Agar data dapat dipahami dengan baik, visualisasi keterkaitan antara fitur-fitur yang ada dengan is_cross_sell perlu dilakukan. Selain untuk lebih memahami karakter data, kami dapat menganalisis lebih jauh hubungan is_cross_sell dengan fitur lainnya. Visualisasi menggunakan scatter plot dan bar plot
sns.scatterplot(data=df_train,x='price',y='member_duration_days',hue='is_cross_sell')
<matplotlib.axes._subplots.AxesSubplot at 0x7f209cead048>
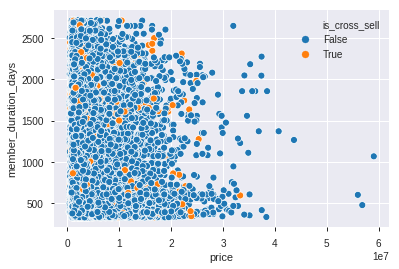
Dapat dilihat dari scatter plot diatas, persebaran dari harga dan durasi member terhadap cross sell menyebar sehingga harga dan durasi member tidak cukup untuk menentukan apakah suatu transaksi terjadi cross sell atau tidak.
sns.countplot(data=df_train,x='is_tx_promo',hue='is_cross_sell')
<matplotlib.axes._subplots.AxesSubplot at 0x7f2090123be0>
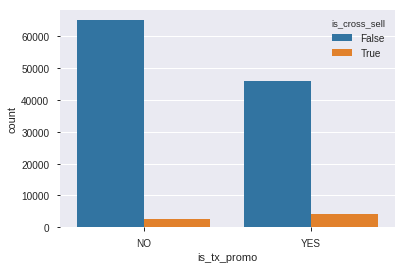
Dari bar plot diatas dapat disimpulkan bahwa baik ada promo maupun tidak, transaksi tanpa cross sell banyak terjadi dengan lebih dari 45000 transaksi.
sns.countplot(data=df_train,x='no_of_seats',hue='is_cross_sell')
<matplotlib.axes._subplots.AxesSubplot at 0x7f20a23d85f8>
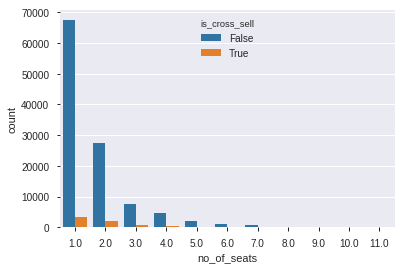
Dapat dilihat bahwa pelanggan yang membeli lebih dari 5 tiket dalam sekali order hampir tidak pernah memesan hotel, asumsi kami bahwa pelanggan yang memesan lebih dari 5 tiket adalah keluarga yang mudik atau berkunjung ke rumah sanak saudara.
sns.countplot(data=df_train,x='trip',hue='is_cross_sell')
<matplotlib.axes._subplots.AxesSubplot at 0x7f2090eb42b0>
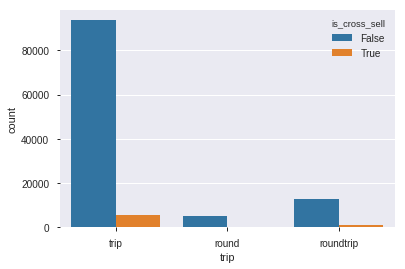
Pada fitur trip, lebih banyak bernilai trip yang melakukan transaksi cross sell. kami menganggap nilai roundtrip dan round merupakan nilai yang sama, karena memiliki definisi yang cukup mirip dan banyak nilai round yang terlalu sedikit.
# nilai unik dari visited_city`
print(df_train['visited_city'].unique())
sns.countplot(data=df_train,x='visited_city',hue='is_cross_sell',orient='v')
[('Semarang', 'Jakarta', 'Medan', 'Bali') ('Jakarta', 'Medan', 'Bali')
('Jogjakarta', 'Bali', 'Jakarta', 'Medan')
('Jakarta', 'Bali', 'Medan', 'Jogjakarta', 'Semarang')
('Bali', 'Jakarta', 'Medan') ('Medan', 'Bali', 'Jakarta')
('Manado', 'Medan', 'Bali', 'Jakarta')
('Surabaya', 'Medan', 'Bali', 'Jakarta', 'Aceh')]
<matplotlib.axes._subplots.AxesSubplot at 0x7f2093580a58>
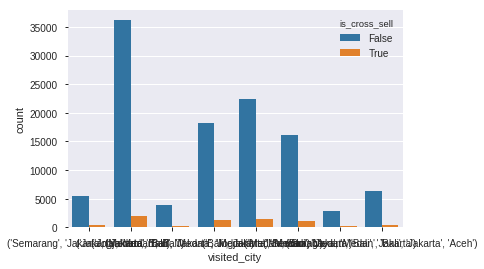
Pelanggan yang pernah mengunjungi ('Jakarta', 'Medan', 'Bali') paling banyak melakukan transaksi cross sell maupun tidak.
sns.countplot(data=df_train,x='service_class',hue='is_cross_sell',orient='v')
<matplotlib.axes._subplots.AxesSubplot at 0x7f209031e198>
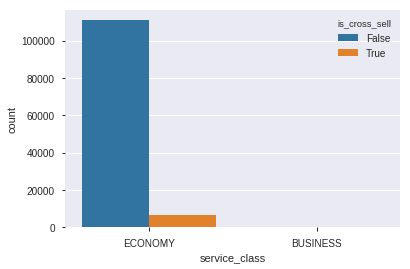
Pada fitur service_class jauh lebih banyak row yang bernilai economy daripada businesss sehingga kami rasa fitur ini tidak layak untuk dianalisa lebih lanjut.
Processing EDA
Dari EDA diatas kami memutuskan untuk melakukan proses berikut:
- Menghapus fitur:
service_class: lebih banyak bernilai economy.route: hanya memiliki satu nilai,log_transaction: sudah mengambil nilai min, max, mean, median, std, sum dan count (Proses ini telah dilakukan bersamaan dengan pengambilan nilai-nilai tersebut).
df_train.drop(['service_class','route'],axis=1,inplace=True)
df_test.drop(['service_class','route'],axis=1,inplace=True)
- Mengkombinasikan nilai menjadi satu pada suatu fitur :
trip: roundtrip dan round menjadi round saja.
df_train['trip'] = np.where(df_train['trip']=='roundtrip', 'round', df_train['trip'])
df_test['trip'] = np.where(df_test['trip']=='roundtrip', 'round', df_test['trip'])
- Mentransformasi nilai pada fitur
member_duration_days,price,max_log_transaction,min_log_transaction,mean_log_transaction,len_log_transaction, dansum_log_transactionyang bertipe numerik menggunakan logaritma natural.
Sebelum melakukan normalisasi, kami terlebih dahulu mengubah nilai negatif pada fitur min_log_transaction menjadi nilai mean fitur tersebut.
df_train['min_log_transaction'] = np.where(df_train['min_log_transaction'] < 0 , df_train['min_log_transaction'].mean(), df_train['min_log_transaction'])
df_test['min_log_transaction'] = np.where(df_test['min_log_transaction'] < 0, df_test['min_log_transaction'].mean(), df_test['min_log_transaction'])
cols = df_train.drop('no_of_seats',axis=1).select_dtypes([np.number]).columns
for col in cols:
df_train[col] = np.log1p(df_train[col])
df_test[col] = np.log1p(df_test[col])
Feature Engineering
New Features
Proses ini merupakan pembuatan fitur baru menggunakan fitur yang sudah ada dan insights yang telah dianalisis pada proses EDA sebelumnya. Pada proses feature engineering ini, kami membuat beberapa fitur baru, yaitu:
count_use_hotel: berapa kali pelanggan bersangkutan memesan hotel?mode_facility_hotel: mode dari fasilitas suatu hotel.mode_rate_hotel: mode rating yang diberikan oleh pelanggan.count_user_id: berapa kali customer melakukan transaksi.count_user_id_with_air: Berapa kali customer memesan dengan maskapai yang sama.how_many_city: berapa kota yang telah pelanggan kunjungi.mean_price_air: rata-rata harga setiap maskapai.price_per_seat: harga untuk tiap kursi yang dipesan.order_rate: jumlah berapa kali customer melakukan transaksi.
Untuk membuat fitur count_use_hotel, kami menggunakan aggregasi account_id dan hotel_id dan menggunakan helper function count_hotel(x) untuk menentukan berapa kali pelanggan tiket.com memesan tiket bersamaan dengan hotel.
Dan untuk fitur yang membutuhkan hotel id terdapat 2 kemungkinan nilai NaN dimana sebuah order memesan hotel yang tidak terdapat pada dataframe hotel atau tidak memesan hotel sama sekali, untuk kasus pertama kami menggunakan -999 untuk mengganti nilai NaN nya dan -1 untuk kasus kedua agar model dapat membedakan kedua kasus tersebut.
# list of account that ever use hotel
account_with_hotel = df_train[df_train['hotel_id']!='None'].groupby('account_id').agg('count')['order_id']
def count_hotel(x):
if x in account_with_hotel:
return account_with_hotel[x]
return 0
# add ever_use_hotel into dataframe
df_train['count_use_hotel'] = df_train['account_id'].apply(count_hotel)
df_test['count_use_hotel'] = df_test['account_id'].apply(count_hotel)
Sebelum membuat fitur mode_facility_hotel, kami tambahkan fitur fasilitas di df_hotel yang berisikan banyak fasilitas yang tersedia pada suatu hotel.
df_hotel["free_wifi_bool"] = np.where(df_hotel["free_wifi"] == 'YES', 1, 0)
df_hotel["pool_access_bool"] = np.where(df_hotel['pool_access'] == 'YES', 1, 0)
df_hotel["free_breakfast_bool"] = np.where(df_hotel['free_breakfast'] == 'YES', 1, 0)
df_hotel['fasilitas'] = df_hotel['free_wifi_bool'] + df_hotel['pool_access_bool'] + df_hotel['free_breakfast_bool']
Untuk membuat fitur mode_facility_hotel, kami menggunakan aggregasi account_id dan fasilitas dan menggunakan helper function mode_facility_hotel(x) untuk menentukan mode fasilitas dari suatu hotel.
# list of mode of facility in a hotel
mode_fasilitas = pd.merge(df_train[df_train['hotel_id']!='None'],df_hotel,on='hotel_id',how='left').fillna(-999).groupby('account_id')['fasilitas'].agg(lambda x:x.value_counts().index[0])
def mode_facilty_hotel(x):
if x in mode_fasilitas:
return mode_fasilitas[x]
return -1
# add mode_facility_hotel into dataframe
df_train['mode_facilty_hotel'] = df_train['account_id'].apply(mode_facilty_hotel)
df_test['mode_facilty_hotel'] = df_test['account_id'].apply(mode_facilty_hotel)
Untuk membuat fitur
mode_star_rating, kami menggunakan mengkombinasikan account_id dan hotel_id sehingga menggunakan helper function mode_rate_hotel(x) untuk menentukan modus dari rating hotel yang digunakan oleh pelanggan.
# list of mode star rating in a hotel
mode_star_rating = pd.merge(df_train[df_train['hotel_id']!='None'],df_hotel,on='hotel_id',how='left').fillna(-999).groupby('account_id')['starRating'].agg(lambda x:x.value_counts().index[0])
def mode_rate_hotel(x):
if x in mode_star_rating:
return mode_star_rating[x]
return -1
# add avg_rate_hotel into dataframe
df_train['mode_rate_hotel'] = df_train['account_id'].apply(mode_rate_hotel)
df_test['mode_rate_hotel'] = df_test['account_id'].apply(mode_rate_hotel)
Untuk membuat fitur count_user_id, kami aggregasi fitur account_id dan order_id untuk melihat jumlah transaksi pada seorang pelanggan.
# Count how many he/she already done an order
df_train['count_user_id'] = df_train.groupby(['account_id'])['order_id'].transform('count')
df_test['count_user_id'] = df_test.groupby(['account_id'])['order_id'].transform('count')
Untuk membuat fitur count_user_id_with_air, kami aggregasi fitur account_id, airlines_name dan order_id untuk melihat jumlah transaksi pada suatu maskapai.
# Count how many he/she already done an order within specified airlines
df_train['count_user_id_with_air'] = df_train.groupby(['account_id','airlines_name'])['order_id'].transform('count')
df_test['count_user_id_with_air'] = df_test.groupby(['account_id','airlines_name'])['order_id'].transform('count')
sns.scatterplot(data=df_train,x='price',y='count_user_id',hue='is_cross_sell')
<matplotlib.axes._subplots.AxesSubplot at 0x7f2090004358>
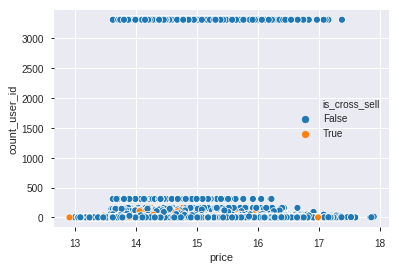
Scatter plot diatas memperlihatkan banyaknya transaksi dan harga penerbangan serta apakah terjadi cross sell atau tidak.
Untuk membuat fitur how_many_city, kami menggunakan fitur visited_city dengn kode dibawah ini sehingga didapatkan jumlah kota yang dikunjungi oleh pelanggan sebelum melakukan transaksi.
# count how many cities was visited
df_train['how_many_city'] = df_train['visited_city'].apply(lambda x: len(x))
df_test['how_many_city'] = df_test['visited_city'].apply(lambda x: len(x))
Kemudian untuk membuat mean_price_air, kami menggunakan aggregasi fitur airlines_name dan price untuk menghitung mean sehingga didapatkan rata-rata harga pada setiap maskapai yang ada.
df_prices = df_train.groupby(['airlines_name'])['price'].mean().reset_index()
df_train = pd.merge(df_train,df_prices,on='airlines_name',how='left')
df_train = df_train.rename(columns={'price_y':'mean_price_air'})
df_prices = df_test.groupby(['airlines_name'])['price'].mean().reset_index()
df_test = pd.merge(df_test,df_prices,on='airlines_name',how='left')
df_test = df_test.rename(columns={'price_y':'mean_price_air'})
Fitur price_per_seat didapatkan dari fitur price_x / no_of_seats, yakni harga pada order dibagi dengan jumlah kursi yang dipesan. Proses tersebut menghasilkan rata-rata harga kursi untuk maskapai terkait.
# Price for each seat
df_train['price_per_seat'] = df_train['price_x']/df_train['no_of_seats']
df_test['price_per_seat'] = df_test['price_x']/df_test['no_of_seats']
Fitur order_rate didapatkan dari fitur len_log_transaction / member_duration_days, yakni banyaknya transaksi yang dilakukan oleh pelanggan dibagi dengan lamanya pelanggan menjadi member tiket.com. Fitur ini mengindikasikan seberapa sering pelanggan melakukan transaksi sejak pelanggan terdaftar menjadi member tiket.com.
# Order Rate of Customer
df_train['order_rate'] = df_train['len_log_transaction']/df_train['member_duration_days']
df_test['order_rate'] = df_test['len_log_transaction']/df_test['member_duration_days']
Berikut ini hasil feature engineering yang telah kami lakukan pada df_train dan df_test:
display(df_train.head())
display(df_test.head())
| account_id | order_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | hotel_id | ... | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | count_user_id | count_user_id_with_air | how_many_city | mean_price_air | price_per_seat | order_rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 912aa410a02cd7e1bab414214a7005c0 | 5c6f39c690f23650d3cde28e5b51c908 | 6.340359 | M | trip | 13.694358 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | None | ... | 13.024431 | 0 | -1.0 | -1.0 | 2 | 1 | 4 | 14.435097 | 13.694358 | 0.253840 |
| 1 | d64a90a618202a5e8b25d8539377f3ca | 5cbef2b87f51c18bf399d11bfe495a46 | 6.410175 | M | trip | 14.576201 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | None | ... | 14.780214 | 0 | -1.0 | -1.0 | 3311 | 575 | 3 | 14.640493 | 7.288100 | 1.090637 |
| 2 | 1a42ac02bcb4a902973123323f84da55 | 38fc35a1e62384012a358ab1fbd5ad03 | 6.475433 | F | trip | 14.807113 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | None | ... | 14.626451 | 0 | -1.0 | -1.0 | 3 | 1 | 4 | 14.640493 | 14.807113 | 0.276701 |
| 3 | 92cddd64d4be4dec6dfbcc0c50e902f4 | c7f54cb748828b4413e02dea2758faf6 | 6.037871 | F | trip | 13.952369 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | None | ... | 14.350099 | 0 | -1.0 | -1.0 | 1 | 1 | 4 | 14.640493 | 13.952369 | 0.229600 |
| 4 | bf637abc47ea93bad22264f4956d67f6 | dec228e4d2b6023c9f1fe9cfe9c451bf | 6.287859 | F | trip | 13.938642 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | None | ... | 14.916300 | 10 | 1.0 | 4.0 | 161 | 103 | 5 | 14.531102 | 13.938642 | 0.805138 |
5 rows × 26 columns
| account_id | order_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | visited_city | ... | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | count_user_id | count_user_id_with_air | how_many_city | mean_price_air | price_per_seat | order_rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 89a5fadd4d596610ff56044b9a0b1f4f | 5ca64fd80a069208e3c0aa05dd580fb8 | 7.470224 | M | trip | 14.960816 | YES | 3 | e35de6a36d385711a660c72c0286154a | (Bali, Jakarta, Medan) | ... | 14.909172 | 0 | -1.0 | -1.0 | 1 | 1 | 3 | 14.751176 | 4.986939 | 0.260489 |
| 1 | 86b28323bec6d938d47cee887e509b28 | aca60904549a8a5958fe7a642efcb534 | 6.989335 | F | trip | 14.588673 | NO | 2 | e35de6a36d385711a660c72c0286154a | (Medan, Bali, Jakarta) | ... | 14.881040 | 0 | -1.0 | -1.0 | 1 | 1 | 3 | 14.751176 | 7.294337 | 0.230271 |
| 2 | 36ef956ac3ef963c48e67327a4b6cc78 | 1771011e3adec5db9f30d15b3d439711 | 7.774436 | M | round | 14.030312 | NO | 1 | ad5bef60d81ea077018f4d50b813153a | (Jakarta, Medan, Bali) | ... | 14.707013 | 0 | -1.0 | -1.0 | 1 | 1 | 3 | 14.475678 | 14.030312 | 0.250296 |
| 3 | f7821289404d44db50eb2edd4f82ea5b | 6fc1b7d590c2a8c539ce56397403194d | 6.357842 | F | trip | 14.500656 | YES | 2 | 33199710eb822fbcfd0dc793f4788d30 | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | ... | 14.746227 | 0 | -1.0 | -1.0 | 1 | 1 | 5 | 14.431748 | 7.250328 | 0.218045 |
| 4 | f62f33d1de5aabc919b69b1b5697f27a | c1f4712f60cd758e773555690d148764 | 6.760415 | F | trip | 14.910993 | YES | 1 | 74c5549aa99d55280a896ea50068a211 | (Bali, Jakarta, Medan) | ... | 14.816352 | 0 | -1.0 | -1.0 | 1 | 1 | 3 | 14.933932 | 14.910993 | 0.205061 |
5 rows × 24 columns
Setelah dianalisis, penggunaan fitur hotel_id tidak diperlukan kembali sehingga perlu dihapus.
df_train.drop(['hotel_id'],axis=1,inplace=True)
Feature Scaling
Pada proses ini bertujuan untuk menyamakan skala nilai dari semua variable dimana terdapat fitur member_duration_days yang skala yang kecil dan fitur lain, yaitu price yang memiliki nilai jutaan.
Standard Scale
Standard Scale merupakan proses untuk menstandarkan fitur dengan mengurangi mean data dan kemudian menskalakannya ke varians unit. Varians unit berarti membagi semua nilai data dengan standar deviasi. Standard Scale menghasilkan distribusi dengan standar deviasi sama dengan 1. Selain itu, Standard Scale membuat rata-rata dari distribusi data menjadi 0.
Pada proses ini mengambil seluruh fitur pada df_train dan df_test yang digabungkan menjadi df_all yang bertipe numerik kecuali feature dengan kardinalitas yang kecil seperti no_of_seats, mode_rate_hotel dan mode_facilty_hotel untuk dilakukan proses scaling. Hasil proses tersebut kemudian disimpan pada dataframe df_train_sc dan df_test_sc.
cols = df_train.drop(['no_of_seats','mode_rate_hotel','mode_facilty_hotel'],axis=1).select_dtypes([np.number]).columns
df_all = pd.concat([df_train.drop('is_cross_sell',axis=1),df_test])
sc = StandardScaler()
for i in cols:
df_all[i] = sc.fit_transform(df_all[i].values.reshape(-1,1))
df_all.set_index('order_id',inplace=True)
df_train_sc = df_all.loc[df_train['order_id'].values].reset_index()
df_test_sc = df_all.loc[df_test['order_id'].values].reset_index()
df_train_sc = pd.merge(df_train_sc,df_train[['order_id','is_cross_sell']],on='order_id')
Saat ini kami memiliki data train dan data test yang discale dan yang tidak discale. Hasil Standar Scale pada df_train_sc dan df_test_sc:
display(df_train_sc.head())
display(df_test_sc.head())
| order_id | account_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | visited_city | ... | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | count_user_id | count_user_id_with_air | how_many_city | mean_price_air | price_per_seat | order_rate | is_cross_sell | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5c6f39c690f23650d3cde28e5b51c908 | 912aa410a02cd7e1bab414214a7005c0 | -0.661036 | M | trip | -1.387447 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | (Semarang, Jakarta, Medan, Bali) | ... | -0.119540 | -1.0 | -1.0 | -0.170508 | -0.165551 | 0.543227 | -0.868480 | 0.651444 | -0.223712 | False |
| 1 | 5cbef2b87f51c18bf399d11bfe495a46 | d64a90a618202a5e8b25d8539377f3ca | -0.534578 | M | trip | 0.015859 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | (Jakarta, Medan, Bali) | ... | -0.119540 | -1.0 | -1.0 | 6.130028 | 3.879247 | -0.661594 | 0.491785 | -0.917180 | 4.937157 | False |
| 2 | 38fc35a1e62384012a358ab1fbd5ad03 | 1a42ac02bcb4a902973123323f84da55 | -0.416376 | F | trip | 0.383319 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | (Semarang, Jakarta, Medan, Bali) | ... | -0.119540 | -1.0 | -1.0 | -0.168604 | -0.165551 | 0.543227 | 0.491785 | 0.923911 | -0.082719 | False |
| 3 | c7f54cb748828b4413e02dea2758faf6 | 92cddd64d4be4dec6dfbcc0c50e902f4 | -1.208935 | F | trip | -0.976865 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | (Jogjakarta, Bali, Jakarta, Medan) | ... | -0.119540 | -1.0 | -1.0 | -0.172412 | -0.165551 | 0.543227 | 0.491785 | 0.714620 | -0.373212 | False |
| 4 | dec228e4d2b6023c9f1fe9cfe9c451bf | bf637abc47ea93bad22264f4956d67f6 | -0.756131 | F | trip | -0.998709 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | ... | 2.448484 | 1.0 | 4.0 | 0.132238 | 0.553211 | 1.748048 | -0.232671 | 0.711258 | 3.176367 | False |
5 rows × 25 columns
| order_id | account_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | visited_city | ... | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | count_user_id | count_user_id_with_air | how_many_city | mean_price_air | price_per_seat | order_rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5ca64fd80a069208e3c0aa05dd580fb8 | 89a5fadd4d596610ff56044b9a0b1f4f | 1.385497 | M | trip | 0.627911 | YES | 3.0 | e35de6a36d385711a660c72c0286154a | (Bali, Jakarta, Medan) | ... | 0.610797 | -0.11954 | -1.0 | -1.0 | -0.172412 | -0.165551 | -0.661594 | 1.224800 | -1.480638 | -0.182707 |
| 1 | aca60904549a8a5958fe7a642efcb534 | 86b28323bec6d938d47cee887e509b28 | 0.514459 | F | trip | 0.035708 | NO | 2.0 | e35de6a36d385711a660c72c0286154a | (Medan, Bali, Jakarta) | ... | 0.567207 | -0.11954 | -1.0 | -1.0 | -0.172412 | -0.165551 | -0.661594 | 1.224800 | -0.915653 | -0.369076 |
| 2 | 1771011e3adec5db9f30d15b3d439711 | 36ef956ac3ef963c48e67327a4b6cc78 | 1.936517 | M | round | -0.852832 | NO | 1.0 | ad5bef60d81ea077018f4d50b813153a | (Jakarta, Medan, Bali) | ... | 0.297556 | -0.11954 | -1.0 | -1.0 | -0.172412 | -0.165551 | -0.661594 | -0.599725 | 0.733705 | -0.245571 |
| 3 | 6fc1b7d590c2a8c539ce56397403194d | f7821289404d44db50eb2edd4f82ea5b | -0.629369 | F | trip | -0.104357 | YES | 2.0 | 33199710eb822fbcfd0dc793f4788d30 | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | ... | 0.358317 | -0.11954 | -1.0 | -1.0 | -0.172412 | -0.165551 | 1.748048 | -0.890659 | -0.926429 | -0.444477 |
| 4 | c1f4712f60cd758e773555690d148764 | f62f33d1de5aabc919b69b1b5697f27a | 0.099814 | F | trip | 0.548626 | YES | 1.0 | 74c5549aa99d55280a896ea50068a211 | (Bali, Jakarta, Medan) | ... | 0.466974 | -0.11954 | -1.0 | -1.0 | -0.172412 | -0.165551 | -0.661594 | 2.435134 | 0.949346 | -0.524556 |
5 rows × 24 columns
mengecek banyaknya data df_train yang terjadi cross sell.
df_train['is_cross_sell'].sum()
6748
Encoding
Encoding yang kami lakukan adalah menggunakan mean encoding dengan smoothing, kami menggunakan ini untuk memberi gambaran distribusi target pada data train untuk model karena kami berasumsi bahwa distribusi nya akan mirip dengan banyak order tidak cross sell jauh mengalahkan banyak order yang cross sell.
Mean Encoding
Salah satu teknik umum dalam feature engineering adalah mengubah kategorikal data menjadi numerik. Mean encoding memperhitungkan jumlah label beserta variabel target untuk diencode labelnya ke dalam nilai yang dapat dipahami model (numerik). Ilustrasi mean encoding terdapat pada gambar dibawah ini.

Untuk Melakukan mean encoding, kami menggunakan helper function calc_smooth_mean() yang akan membantu untuk melakukan mean encoding pada fitur tertentu. Fitur yang akan dilakukan proses mean encoding adalah gender, trip, is_tx_promo, no_of_seats, airlines_name, dan visited_city.
def calc_smooth_mean(df, by, on, m):
# Compute the global mean
mean = df[on].mean()
# Compute the number of values and the mean of each group
agg = df.groupby(by)[on].agg(['count', 'mean'])
counts = agg['count']
means = agg['mean']
# Compute the "smoothed" means
smooth = (counts * means + m * mean) / (counts + m)
# Replace each value by the according smoothed mean
return df[by].map(smooth),means
- Mean encoding pada fitur
gender
df_train['gender_enc'] = calc_smooth_mean(df_train, 'gender', 'is_cross_sell', m=300)[0]
df_train_sc['gender_enc'] = calc_smooth_mean(df_train_sc, 'gender', 'is_cross_sell', m=300)[0]
gender_enc = calc_smooth_mean(df_train, 'gender', 'is_cross_sell', m=300)[1]
df_test['gender_enc'] = df_test['gender'].apply(lambda x:gender_enc[x])
df_test_sc['gender_enc'] = df_test_sc['gender'].apply(lambda x:gender_enc[x])
- Mean encoding pada fitur
trip
df_train['trip_enc'] = calc_smooth_mean(df_train, 'trip', 'is_cross_sell', m=300)[0]
df_train_sc['trip_enc'] = calc_smooth_mean(df_train_sc, 'trip', 'is_cross_sell', m=300)[0]
trip_enc = calc_smooth_mean(df_train, 'trip', 'is_cross_sell', m=300)[1]
df_test['trip_enc'] = df_test['trip'].apply(lambda x:trip_enc[x])
df_test_sc['trip_enc'] = df_test_sc['trip'].apply(lambda x:trip_enc[x])
- Mean encoding pada fitur
is_tx_promo
df_train['promo_enc'] = calc_smooth_mean(df_train, 'is_tx_promo', 'is_cross_sell', m=300)[0]
df_train_sc['promo_enc'] = calc_smooth_mean(df_train_sc, 'is_tx_promo', 'is_cross_sell', m=300)[0]
promo_enc = calc_smooth_mean(df_train, 'is_tx_promo', 'is_cross_sell', m=300)[1]
df_test['promo_enc'] = df_test['is_tx_promo'].apply(lambda x:promo_enc[x])
df_test_sc['promo_enc'] = df_test_sc['is_tx_promo'].apply(lambda x:promo_enc[x])
- Mean encoding pada fitur
no_of_seats
df_train['seats_enc'] = calc_smooth_mean(df_train, 'no_of_seats', 'is_cross_sell', m=300)[0]
df_train_sc['seats_enc'] = calc_smooth_mean(df_train_sc, 'no_of_seats', 'is_cross_sell', m=300)[0]
seats_enc = calc_smooth_mean(df_train, 'no_of_seats', 'is_cross_sell', m=300)[1]
df_test['seats_enc'] = df_test['no_of_seats'].apply(lambda x:seats_enc[x])
df_test_sc['seats_enc'] = df_test_sc['no_of_seats'].apply(lambda x:seats_enc[x])
- Mean encoding pada fitur
airlines_name
df_train['air_enc'] = calc_smooth_mean(df_train, 'airlines_name', 'is_cross_sell', m=300)[0]
df_train_sc['air_enc'] = calc_smooth_mean(df_train_sc, 'airlines_name', 'is_cross_sell', m=300)[0]
air_enc = calc_smooth_mean(df_train, 'airlines_name', 'is_cross_sell', m=300)[1]
df_test['air_enc'] = df_test['airlines_name'].apply(lambda x:air_enc[x])
df_test_sc['air_enc'] = df_test_sc['airlines_name'].apply(lambda x:air_enc[x])
- Mean encoding pada fitur
visited_city
df_train['visited_city_enc'] = calc_smooth_mean(df_train, 'visited_city', 'is_cross_sell', m=300)[0]
df_train_sc['visited_city_enc'] = calc_smooth_mean(df_train_sc, 'visited_city', 'is_cross_sell', m=300)[0]
visited_city_enc = calc_smooth_mean(df_train, 'visited_city', 'is_cross_sell', m=300)[1]
df_test['visited_city_enc'] = df_test['visited_city'].apply(lambda x:visited_city_enc[x])
df_test_sc['visited_city_enc'] = df_test_sc['visited_city'].apply(lambda x:visited_city_enc[x])
Hasil mean encoding pada df_train dan df_test:
display(df_train.head())
display(df_test.head())
| account_id | order_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | visited_city | ... | how_many_city | mean_price_air | price_per_seat | order_rate | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 912aa410a02cd7e1bab414214a7005c0 | 5c6f39c690f23650d3cde28e5b51c908 | 6.340359 | M | trip | 13.694358 | NO | 1.0 | 33199710eb822fbcfd0dc793f4788d30 | (Semarang, Jakarta, Medan, Bali) | ... | 4 | 14.435097 | 13.694358 | 0.253840 | 0.054131 | 0.055719 | 0.037163 | 0.049303 | 0.046482 | 0.060278 |
| 1 | d64a90a618202a5e8b25d8539377f3ca | 5cbef2b87f51c18bf399d11bfe495a46 | 6.410175 | M | trip | 14.576201 | NO | 2.0 | 0a102015e48c1f68e121acc99fca9a05 | (Jakarta, Medan, Bali) | ... | 3 | 14.640493 | 7.288100 | 1.090637 | 0.054131 | 0.055719 | 0.037163 | 0.070097 | 0.059034 | 0.050315 |
| 2 | 1a42ac02bcb4a902973123323f84da55 | 38fc35a1e62384012a358ab1fbd5ad03 | 6.475433 | F | trip | 14.807113 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | (Semarang, Jakarta, Medan, Bali) | ... | 4 | 14.640493 | 14.807113 | 0.276701 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.060278 |
| 3 | 92cddd64d4be4dec6dfbcc0c50e902f4 | c7f54cb748828b4413e02dea2758faf6 | 6.037871 | F | trip | 13.952369 | NO | 1.0 | 0a102015e48c1f68e121acc99fca9a05 | (Jogjakarta, Bali, Jakarta, Medan) | ... | 4 | 14.640493 | 13.952369 | 0.229600 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.057819 |
| 4 | bf637abc47ea93bad22264f4956d67f6 | dec228e4d2b6023c9f1fe9cfe9c451bf | 6.287859 | F | trip | 13.938642 | NO | 1.0 | 6c483c0812c96f8ec43bb0ff76eaf716 | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | ... | 5 | 14.531102 | 13.938642 | 0.805138 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059379 | 0.062092 |
5 rows × 31 columns
| account_id | order_id | member_duration_days | gender | trip | price_x | is_tx_promo | no_of_seats | airlines_name | visited_city | ... | how_many_city | mean_price_air | price_per_seat | order_rate | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 89a5fadd4d596610ff56044b9a0b1f4f | 5ca64fd80a069208e3c0aa05dd580fb8 | 7.470224 | M | trip | 14.960816 | YES | 3 | e35de6a36d385711a660c72c0286154a | (Bali, Jakarta, Medan) | ... | 3 | 14.751176 | 4.986939 | 0.260489 | 0.054116 | 0.055715 | 0.084272 | 0.074429 | 0.062465 | 0.058189 |
| 1 | 86b28323bec6d938d47cee887e509b28 | aca60904549a8a5958fe7a642efcb534 | 6.989335 | F | trip | 14.588673 | NO | 2 | e35de6a36d385711a660c72c0286154a | (Medan, Bali, Jakarta) | ... | 3 | 14.751176 | 7.294337 | 0.230271 | 0.060525 | 0.055715 | 0.037074 | 0.070228 | 0.062465 | 0.066370 |
| 2 | 36ef956ac3ef963c48e67327a4b6cc78 | 1771011e3adec5db9f30d15b3d439711 | 7.774436 | M | round | 14.030312 | NO | 1 | ad5bef60d81ea077018f4d50b813153a | (Jakarta, Medan, Bali) | ... | 3 | 14.475678 | 14.030312 | 0.250296 | 0.054116 | 0.065113 | 0.037074 | 0.049269 | 0.074769 | 0.050261 |
| 3 | f7821289404d44db50eb2edd4f82ea5b | 6fc1b7d590c2a8c539ce56397403194d | 6.357842 | F | trip | 14.500656 | YES | 2 | 33199710eb822fbcfd0dc793f4788d30 | (Jakarta, Bali, Medan, Jogjakarta, Semarang) | ... | 5 | 14.431748 | 7.250328 | 0.218045 | 0.060525 | 0.055715 | 0.084272 | 0.070228 | 0.046377 | 0.062168 |
| 4 | f62f33d1de5aabc919b69b1b5697f27a | c1f4712f60cd758e773555690d148764 | 6.760415 | F | trip | 14.910993 | YES | 1 | 74c5549aa99d55280a896ea50068a211 | (Bali, Jakarta, Medan) | ... | 3 | 14.933932 | 14.910993 | 0.205061 | 0.060525 | 0.055715 | 0.084272 | 0.049269 | 0.054228 | 0.058189 |
5 rows × 30 columns
Drop Some Features
Proses terakhir dalam feature engineering kami adalah menghapus fitur-fitur category karena telah digantikan dengan counterpart mereka yang telah di encoding.
def drop_ever(df):
df.drop('gender',axis=1,inplace=True)
df.drop('trip',axis=1,inplace=True)
df.drop('is_tx_promo',axis=1,inplace=True)
df.drop('no_of_seats',axis=1,inplace=True)
df.drop('airlines_name',axis=1,inplace=True)
df.drop('visited_city',axis=1,inplace=True)
df.drop(['account_id','order_id'],axis=1,inplace=True)
drop_ever(df_train)
drop_ever(df_test)
drop_ever(df_train_sc)
drop_ever(df_test_sc)
Hasil dari proses-proses sebelumnya pada df_train dan df_test:
display(df_train.head())
display(df_train.shape)
display(df_test.head())
display(df_test.shape)
| member_duration_days | price_x | is_cross_sell | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | count_use_hotel | mode_facilty_hotel | ... | how_many_city | mean_price_air | price_per_seat | order_rate | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6.340359 | 13.694358 | False | 14.388884 | 13.208915 | 13.846001 | 1.609438 | 13.024431 | 0 | -1.0 | ... | 4 | 14.435097 | 13.694358 | 0.253840 | 0.054131 | 0.055719 | 0.037163 | 0.049303 | 0.046482 | 0.060278 |
| 1 | 6.410175 | 14.576201 | False | 16.743283 | 13.227583 | 14.788710 | 6.991177 | 14.780214 | 0 | -1.0 | ... | 3 | 14.640493 | 7.288100 | 1.090637 | 0.054131 | 0.055719 | 0.037163 | 0.070097 | 0.059034 | 0.050315 |
| 2 | 6.475433 | 14.807113 | False | 15.807344 | 14.474771 | 15.317246 | 1.791759 | 14.626451 | 0 | -1.0 | ... | 4 | 14.640493 | 14.807113 | 0.276701 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.060278 |
| 3 | 6.037871 | 13.952369 | False | 15.472525 | 13.952369 | 14.898969 | 1.386294 | 14.350099 | 0 | -1.0 | ... | 4 | 14.640493 | 13.952369 | 0.229600 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.057819 |
| 4 | 6.287859 | 13.938642 | False | 16.422925 | 13.765942 | 15.288487 | 5.062595 | 14.916300 | 10 | 1.0 | ... | 5 | 14.531102 | 13.938642 | 0.805138 | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059379 | 0.062092 |
5 rows × 23 columns
(117946, 23)
| member_duration_days | price_x | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | ... | how_many_city | mean_price_air | price_per_seat | order_rate | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.470224 | 14.960816 | 15.886192 | 12.410176 | 14.963379 | 1.945910 | 14.909172 | 0 | -1.0 | -1.0 | ... | 3 | 14.751176 | 4.986939 | 0.260489 | 0.054116 | 0.055715 | 0.084272 | 0.074429 | 0.062465 | 0.058189 |
| 1 | 6.989335 | 14.588673 | 16.109695 | 14.588673 | 15.614947 | 1.609438 | 14.881040 | 0 | -1.0 | -1.0 | ... | 3 | 14.751176 | 7.294337 | 0.230271 | 0.060525 | 0.055715 | 0.037074 | 0.070228 | 0.062465 | 0.066370 |
| 2 | 7.774436 | 14.030312 | 15.864208 | 12.427091 | 14.936979 | 1.945910 | 14.707013 | 0 | -1.0 | -1.0 | ... | 3 | 14.475678 | 14.030312 | 0.250296 | 0.054116 | 0.065113 | 0.037074 | 0.049269 | 0.074769 | 0.050261 |
| 3 | 6.357842 | 14.500656 | 15.629852 | 10.984279 | 14.818595 | 1.386294 | 14.746227 | 0 | -1.0 | -1.0 | ... | 5 | 14.431748 | 7.250328 | 0.218045 | 0.060525 | 0.055715 | 0.084272 | 0.070228 | 0.046377 | 0.062168 |
| 4 | 6.760415 | 14.910993 | 16.082854 | 14.910993 | 15.664584 | 1.386294 | 14.816352 | 0 | -1.0 | -1.0 | ... | 3 | 14.933932 | 14.910993 | 0.205061 | 0.060525 | 0.055715 | 0.084272 | 0.049269 | 0.054228 | 0.058189 |
5 rows × 22 columns
(10000, 22)
display(df_train_sc.head())
display(df_train_sc.shape)
display(df_test_sc.head())
display(df_test_sc.shape)
| member_duration_days | price_x | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | ... | mean_price_air | price_per_seat | order_rate | is_cross_sell | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.661036 | -1.387447 | -3.013092 | -0.701810 | -3.180068 | -0.310166 | -2.309567 | -0.119540 | -1.0 | -1.0 | ... | -0.868480 | 0.651444 | -0.223712 | False | 0.054131 | 0.055719 | 0.037163 | 0.049303 | 0.046482 | 0.060278 |
| 1 | -0.534578 | 0.015859 | 2.040763 | -0.681693 | -0.850595 | 4.832445 | 0.410979 | -0.119540 | -1.0 | -1.0 | ... | 0.491785 | -0.917180 | 4.937157 | False | 0.054131 | 0.055719 | 0.037163 | 0.070097 | 0.059034 | 0.050315 |
| 2 | -0.416376 | 0.383319 | 0.031715 | 0.662335 | 0.455440 | -0.135946 | 0.172726 | -0.119540 | -1.0 | -1.0 | ... | 0.491785 | 0.923911 | -0.082719 | False | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.060278 |
| 3 | -1.208935 | -0.976865 | -0.686993 | 0.099370 | -0.578140 | -0.523395 | -0.255474 | -0.119540 | -1.0 | -1.0 | ... | 0.491785 | 0.714620 | -0.373212 | False | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059034 | 0.057819 |
| 4 | -0.756131 | -0.998709 | 1.353096 | -0.101532 | 0.384374 | 2.989556 | 0.621841 | 2.448484 | 1.0 | 4.0 | ... | -0.232671 | 0.711258 | 3.176367 | False | 0.060507 | 0.055719 | 0.037163 | 0.049303 | 0.059379 | 0.062092 |
5 rows × 23 columns
(117946, 23)
| member_duration_days | price_x | max_log_transaction | min_log_transaction | mean_log_transaction | len_log_transaction | sum_log_transaction | count_use_hotel | mode_facilty_hotel | mode_rate_hotel | ... | how_many_city | mean_price_air | price_per_seat | order_rate | gender_enc | trip_enc | promo_enc | seats_enc | air_enc | visited_city_enc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.385497 | 0.627911 | 0.200968 | -1.562569 | -0.418982 | 0.011355 | 0.610797 | -0.11954 | -1.0 | -1.0 | ... | -0.661594 | 1.224800 | -1.480638 | -0.182707 | 0.054116 | 0.055715 | 0.084272 | 0.074429 | 0.062465 | 0.058189 |
| 1 | 0.514459 | 0.035708 | 0.680730 | 0.785081 | 1.191071 | -0.310166 | 0.567207 | -0.11954 | -1.0 | -1.0 | ... | -0.661594 | 1.224800 | -0.915653 | -0.369076 | 0.060525 | 0.055715 | 0.037074 | 0.070228 | 0.062465 | 0.066370 |
| 2 | 1.936517 | -0.852832 | 0.153778 | -1.544341 | -0.484216 | 0.011355 | 0.297556 | -0.11954 | -1.0 | -1.0 | ... | -0.661594 | -0.599725 | 0.733705 | -0.245571 | 0.054116 | 0.065113 | 0.037074 | 0.049269 | 0.074769 | 0.050261 |
| 3 | -0.629369 | -0.104357 | -0.349281 | -3.099183 | -0.776748 | -0.523395 | 0.358317 | -0.11954 | -1.0 | -1.0 | ... | 1.748048 | -0.890659 | -0.926429 | -0.444477 | 0.060525 | 0.055715 | 0.084272 | 0.070228 | 0.046377 | 0.062168 |
| 4 | 0.099814 | 0.548626 | 0.623114 | 1.132428 | 1.313726 | -0.523395 | 0.466974 | -0.11954 | -1.0 | -1.0 | ... | -0.661594 | 2.435134 | 0.949346 | -0.524556 | 0.060525 | 0.055715 | 0.084272 | 0.049269 | 0.054228 | 0.058189 |
5 rows × 22 columns
(10000, 22)
Modelling
Untuk modelling, kami menggunakan beberapa algoritma klasik machine learning hingga beberapa teknik ensemble seperti voting dan blending untuk didapatkan nilai evaluasi yang terbaik. Selain itu, kami juga memproses data sehingga data seimbang antara transaksi yang terjadi cross sell dan tidak. Untuk tahap awal, kami menggunakan beberapa model dan menginisiasinya.
# Inisiasi Semua Model
xgb_1 = XGBClassifier(n_estimators=100)
lgb_1 = LGBMClassifier(n_estimators=100)
et_1 = ExtraTreesClassifier(n_estimators=100)
rf_1 = RandomForestClassifier(n_estimators=100)
cb_1 = CatBoostClassifier(n_estimators=100, silent=True,loss_function='Logloss')
ada_1 = AdaBoostClassifier(base_estimator=ExtraTreesClassifier(n_estimators=100))
models = {'xgb':xgb_1, 'lgb':lgb_1, 'cb':cb_1, 'et':et_1, 'rf':rf_1, 'ada':ada_1}
Cross Validation
Agar hasil evaluasi menjadi lebih presisi, kami menggunakan cross validation untuk mengevaluasi model yang akan digunakan untuk memprediksi cross sell, adapun K yang digunakan adalah K=5 (ilustrasi dapat dilihat pada gambar dibawah). Evaluasi model dilakukan menggunakan F1-score sesuai dengan ketentuan.
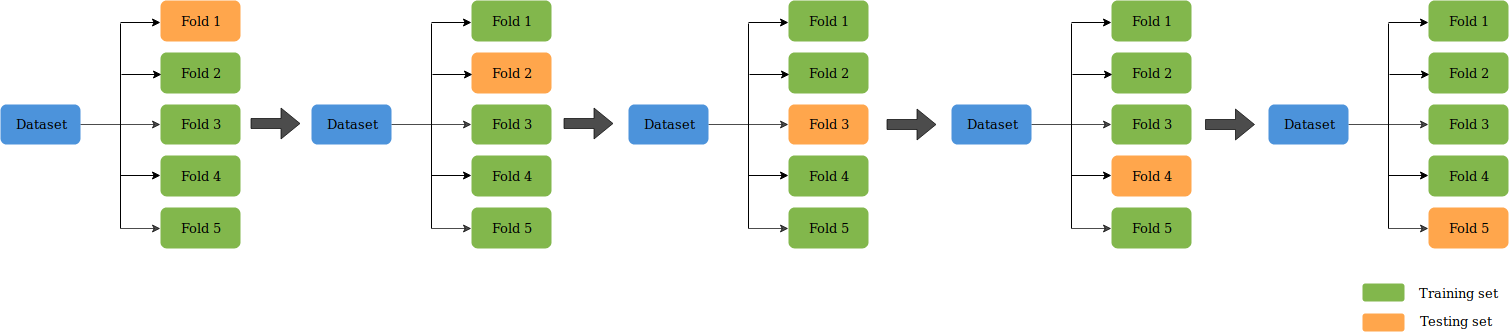
Juga karena tujuan kami menggunakan teknik ensemble maka kami menggunakan Cross Validasi disini untuk menentukan model-model mana saja yang akan digunakan sebagai base estimator.
kf = KFold(n_splits=5)
def cross_val(model, sampling):
imba_pipeline = make_pipeline(sampling, model)
res = cross_val_score(imba_pipeline, X_scaled.values, y_scaled.astype(int), scoring='f1', cv=kf)
return res
# Dataset untuk modelling yang tidak discale dan yang discale
X, y = df_train.drop(['is_cross_sell'],axis=1), df_train['is_cross_sell'].astype(bool)
X_scaled, y_scaled = df_train_sc.drop(['is_cross_sell'],axis=1), df_train_sc['is_cross_sell'].astype(bool)
Kami menggunakan oversampling dengan teknik SMOTE untuk mengatasi data yang imbalance kemudian mengevaluasi masing-masing model yang telah didefinisikan sebelumnya.
Ilustrasi teknik SMOTE sebagai berikut:
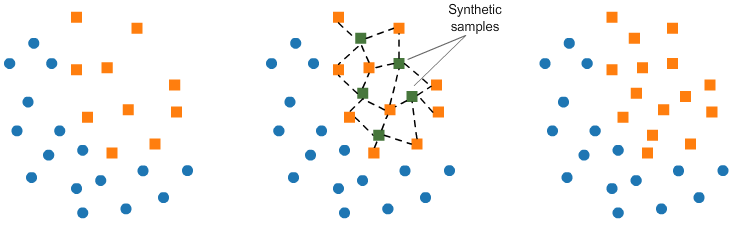
for model in models:
res = cross_val(models[model],SMOTE(random_state=42))
print(f'{model} : {np.mean(res)} +- {np.std(res)}')
xgb : 0.8040062971727762 +- 0.00976663371514552
lgb : 0.8531939808533864 +- 0.011945998072817885
cb : 0.8462804413768813 +- 0.012424279811237702
et : 0.8419926875957617 +- 0.009441331931789896
rf : 0.8482162835667142 +- 0.009658381496305128
ada : 0.8401772047144351 +- 0.00928256212150458
Blending
Blending memiliki pendekatan yang sama dengan stacking, akan tetapi untuk melakukan prediksi hanya menggunakan data validasi. Sebagai contoh, jika digunakan model A dan model B untuk melakukan prediksi, hal yang pertama dilakukan adalah memprediksi data validasi dan data test menggunakan kedua model tersebut. Kemudian hasil prediksi masing-masing model digunakan sebagai fitur baru pada data validasi dan data test. Sehingga model baru C akan menggunakan data validasi dan data test yang sudah terdapat fitur terbaru tersebut untuk difit pada model C dan kemudian memprediksi data test. Dibawah ini merupakan ilustrasi dari blending.

Pada proses blending yang kami lakukan juga digunakan cross validation agar mengetahui performansi model dengan komprehensif.
Arsitektur
Dari hasil diatas kami menggunakan 4 model terbaik yaitu Catboost, Lightgbm, Random Forest dan Extra Tree untuk menjadi base estimator untuk model blending.
n_folds = 10
verbose = True
shuffle = False
sm = SMOTE(random_state=42)
X_scaled_resampled, y_sc_resampled = sm.fit_sample(X_scaled,y_scaled.astype(int))
skf = StratifiedKFold(n_folds)
## Inisialisasi model untuk level 1
clfs = [RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
LGBMClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=100)]
print("Creating train and test sets for blending.")
## Inisialisasi dataset penampung hasil predict dari model level 1 untuk dijadikan fitur di model level 2
dataset_blend_train = np.zeros((X_scaled_resampled.shape[0], len(clfs)))
dataset_blend_test = np.zeros((df_test_sc.shape[0], len(clfs)))
## Untuk setiap model di level 1
for j, clf in enumerate(clfs):
print(j, clf)
dataset_blend_test_j = np.zeros((df_test_sc.shape[0], n_folds))
i=0
## Untuk setiap fold model tersebut akan difit dengan fold tersebut dan dipakai untuk mempredict df_test_sc
for train, test in skf.split(X_scaled_resampled,y_sc_resampled):
print("Fold", i+1)
X_train = X_scaled_resampled[train]
y_train = y_sc_resampled[train]
X_test = X_scaled_resampled[test]
y_test = y_sc_resampled[test]
clf.fit(X_train, y_train)
y_submission = clf.predict(X_test)
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict(df_test_sc)
i+=1
## untuk setiap model kami mengambil rata-rata dari hasil prediksi di setiap fold
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
## Level 2
print()
print("Blending.")
clf = CatBoostClassifier(silent=True) ## inisialisasi model Level 2
clf.fit(dataset_blend_train, y_sc_resampled.astype(int)) ## Fit hasil dataset dari level 1 diatas ke level 2
y_submission = clf.predict(dataset_blend_test) ## predict menggunakan classifier level 2
Creating train and test sets for blending.
0 RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=-1, oob_score=False, random_state=None, verbose=0,
warm_start=False)
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Fold 10
1 RandomForestClassifier(bootstrap=True, class_weight=None, criterion='entropy',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=-1, oob_score=False, random_state=None, verbose=0,
warm_start=False)
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Fold 10
2 ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Fold 10
3 ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='entropy',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Fold 10
4 LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.05, max_depth=6,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True,
subsample=0.5, subsample_for_bin=200000, subsample_freq=0)
Fold 1
Fold 2
Fold 3
Fold 4
Fold 5
Fold 6
Fold 7
Fold 8
Fold 9
Fold 10
Blending.
Submission
Setelah model yang dibuat menghasilkan evaluasi yang baik, kami submit file prediksi.
sample['is_cross_sell'] = y_submission ## ganti value dengan hasil prediksi
sample['is_cross_sell'] = np.where(sample['is_cross_sell']==1.0, 'yes', 'no') ## menyamakan format submisi
sample['is_cross_sell'].value_counts() ## Sanity check
no 8852
yes 1148
Name: is_cross_sell, dtype: int64
sample.to_csv('submission_blending_newfeat_fikhri.csv',index=False) ## Smpan file
Sour Soup © 2019